Chapter 8. Monitoring and Auditing AFS Performance
AFS comes with three main monitoring tools:
The scout program, which monitors and gathers statistics on File Server performance.
The fstrace command suite, which traces Cache Manager operations in detail.
The afsmonitor program, which monitors and gathers statistics on both the File Server and the Cache Manager.
AFS also provides a tool for auditing AFS events on file server machines running AIX.
Summary of Instructions
This chapter explains how to perform the following tasks by using the indicated commands:
| Initialize the scout program | scout |
| Display information about a trace log | fstrace lslog |
| Display information about an event set | fstrace lsset |
| Change the size of a trace log | fstrace setlog |
| Set the state of an event set | fstrace setset |
| Dump contents of a trace log | fstrace dump |
| Clear a trace log | fstrace clear |
| Initialize the afsmonitor program | afsmonitor |
Using the scout Program
The scout program monitors the status of the File Server process running on file server machines. It periodically collects statistics from a specified set of File Server processes, displays them in a graphical format, and alerts you if any of the statistics exceed a configurable threshold.
More specifically, the scout program includes the following features.
You can monitor, from a single location, the File Server process on any number of server machines from the local and foreign cells. The number is limited only by the size of the display window, which must be large enough to display the statistics.
You can set a threshold for many of the statistics. When the value of a statistic exceeds the threshold, the scout program highlights it (displays it in reverse video) to draw your attention to it. If the value goes back under the threshold, the highlighting is deactivated. You control the thresholds, so highlighting reflects what you consider to be a noteworthy situation. See Highlighting Significant Statistics.
The scout program alerts you to File Server process, machine, and network outages by highlighting the name of each machine that does not respond to its probe, enabling you to respond more quickly.
You can set how often the scout program collects statistics from the File Server processes.
System Requirements
The scout program runs on any AFS client machine that has access to the curses graphics package, which most UNIX distributions include as a standard utility. It can run on both dumb terminals and under windowing systems that emulate terminals, but the output looks best on machines that support reverse video and cursor addressing. For best results, set the TERM environment variable to the correct terminal type, or one with characteristics similar to the actual ones. For machines running AIX, the recommended TERM setting is vt100, assuming the terminal is similar to that. For other operating systems, the wider range of acceptable values includes xterm, xterms, vt100, vt200, and wyse85.
No privilege is required to run the scout program, so any user who can access the directory where its binary resides (the /usr/afsws/bin directory in the conventional configuration) can use it. The program's probes for collecting statistics do not impose a significant burden on the File Server process, but you can restrict its use by placing the binary file in a directory with a more restrictive access control list (ACL).
Multiple instances of the scout program can run on a single client machine, each over its own dedicated connection (in its own window). It must run in the foreground, so the window in which it runs does not accept further input except for an interrupt signal.
You can also run the scout program on several machines and view its output on a single machine, by opening telnet connections to the other machines from the central one and initializing the program in each remote window. In this case, you can include the -host flag to the scout command to make the name of each remote machine appear in the banner line at the top of the window displaying its output. See The Banner Line.
Using the -basename argument to Specify a Domain Name
As previously mentioned, the scout program can monitor the File Server process on any number of file server machines. If all of the machines belong to the same cell, then their hostnames probably all have the same domain name suffix, such as abc.com in the ABC Corporation cell. In this case, you can use the -basename argument to the scout command, which has several advantages:
You can omit the domain name suffix as you enter each file server machine's name on the command line. The scout program automatically appends the domain name to each machine's name, resulting in a fully-qualified hostname. You can omit the domain name suffix even when you don't include the -basename argument, but in that case correct resolution of the name depends on the state of your cell's naming service at the time of connection.
The machine names are more likely to fit in the appropriate column of the display without having to be truncated (for more on truncating names in the display column, see The Statistics Display Region).
The domain name appears in the banner line at the top of the display window to indicate the name of the cell you are monitoring.
The Layout of the scout Display
The scout program can display statistics either in a dedicated window or on a plain screen if a windowing environment is not available. For best results, use a window or screen that can print in reverse video and do cursor addressing.
The scout program screen has three main regions: the banner line, the statistics display region and the probe/message line. This section describes their contents, and graphic examples appear in Example Commands and Displays.
The Banner Line
By default, the string scout appears in the banner line at the top of the window or screen, to indicate that the scout program is running. You can display two additional types of information by include the appropriate option on the command line:
Include the -host flag to display the local machine's name in the banner line. This is particularly useful when you are running the scout program on several machines but displaying the results on a single machine.
For example, the following banner line appears when you run the scout program on the machine client1.abc.com and use the-host flag:
[client1.abc.com] scout
Include the -basename argument to display the specified cell domain name in the banner line. For further discussion, see Using the -basename argument to Specify a Domain Name.
For example, if you specify a value of abc.com for the -basename argument, the banner line reads:
scout for abc.com
The Statistics Display Region
The statistics display region occupies most of the window and is divided into six columns. The following list describes them as they appear from left to right in the window.
- Conn
Displays the number of RPC connections open between the File Server process and client machines. This number normally equals or exceeds the number in the fourth Ws column. It can exceed the number in that column because each user on the machine can have more than one connection open at once, and one client machine can handle several users.
- Fetch
Displays the number of fetch-type RPCs (fetch data, fetch access list, and fetch status) that the File Server process has received from client machines since it started. It resets to zero when the File Server process restarts.
- Store
Displays the number of store-type RPCs (store data, store access list, and store status) that the File Server process has received from client machines since it started. It resets to zero when the File Server process restarts.
- Ws
Displays the number of client machines (workstations) that have communicated with the File Server process within the last 15 minutes (such machines are termed active). This number is likely to be smaller than the number in the Conn) column because a single client machine can have several connections open to one File Server process.
- [Unlabeled column]
Displays the name of the file server machine on which the File Server process is running. It is 12 characters wide. Longer names are truncated and an asterisk (*) appears as the last character in the name. If all machines have the same domain name suffix, you can use the -basename argument to decrease the need for truncation; see Using the -basename argument to Specify a Domain Name.
- Disk attn
Displays the number of kilobyte blocks available on up to 26 of the file server machine's AFS server (/vicep) partitions. The display for each partition has the following format:
partition_letter:free_blocks
For example, a:8949 indicates that partition /vicepa has 8,949 KB free. If the window is not wide enough for all partition entries to appear on a single line, the scout program automatically stacks the partition entries into subcolumns within the sixth column.
The label on the Disk attn column indicates the threshold value at which entries in the column become highlighted. By default, the scout program highlights a partition that is over 95% full, in which case the label is as follows:
Disk attn: > 95% used
For more on this threshold and its effect on highlighting, see Highlighting Significant Statistics.
For all columns except the fifth (file server machine name), you can use the -attention argument to set a threshold value above which the scout program highlights the statistic. By default, only values in the fifth and sixth columns ever become highlighted. For instructions on using the -attention argument, see Highlighting Significant Statistics.
The Probe Reporting Line
The bottom line of the display indicates how many times the scout program has probed the File Server processes for statistics. The statistics gathered in the latest probe appear in the statistics display region. By default, the scout program probes the File Servers every 60 seconds, but you can use the -frequency argument to specify a different probe frequency.
Highlighting Significant Statistics
To draw your attention to a statistic that currently exceed a threshold value, the scout program displays it in reverse video (highlights it). You can set the threshold value for most statistics, and so determine which values are worthy of special attention and which are normal.
Highlighting Server Outages
The only column in which you cannot control highlighting is the fifth, which identifies the file server machine for which statistics are displayed in the other columns. The scout program uses highlighting in this column to indicate that the File Server process on a machine fails to respond to its probe, and automatically blanks out the other columns. Failure to respond to the probe can indicate a File Server process, file server machine, or network outage, so the highlighting draws your attention to a situation that is probably interrupting service to users.
When the File Server process once again responds to the probes, its name appears normally and statistics reappear in the other columns. If all machine names become highlighted at once, a possible network outage has disrupted the connection between the file server machines and the client machine running the scout program.
Highlighting for Extreme Statistic Values
To set the threshold value for one or more of the five statistics-displaying columns, use the -attention argument. The threshold value applies to all File Server processes you are monitoring (you cannot set different thresholds for different machines). For details, see the syntax description in To start the scout program.
It is not possible to change the threshold values for a running scout program. Stop the current program and start a new one. Also, the scout program does not retain threshold values across restarts, so you must specify all thresholds every time you start the program.
Resizing the scout Display
Do not resize the display window while the scout program is running. Increasing the size does no harm, but the scout program does not necessarily adjust to the new dimensions. Decreasing the display's width can disturb column alignment, making the display harder to read. With any type of resizing, the scout program does not adjust the display in any way until it displays the results of the next probe.
To resize the display effectively, stop the scout program, resize the window and then restart the program. Even in this case, the scout program's response depends on the accuracy of the information it receives from the display environment. Testing during development has shown that the display environment does not reliably provide information about window resizing. If you use the X windowing system, issuing the following sequence of commands before starting the scout program (or placing them in the shell initialization file) sometimes makes it adjust properly to resizing.
% set noglob % eval '/usr/bin/X11/resize' % unset noglob
To start the scout program
Open a dedicated command shell. If necessary, adjust it to the appropriate size.
Issue the scout command to start the program.
% scout [initcmd] -server <FileServer name(s) to monitor>+ \ [-basename <base server name>] \ [-frequency <poll frequency, in seconds>] [-host] \ [-attention <specify attention (highlighting) level>+] \ [-debug <turn debugging output on to the named file>]
where
- initcmd
Is an optional string that accommodates the command's use of the AFS command parser. It can be omitted and ignored.
- -server
Identifies each File Server process to monitor, by naming the file server machine it is running on. Provide fully-qualified hostnames unless the -basename argument is used. In that case, specify only the initial part of each machine name, omitting the domain name suffix common to all the machine names.
- -basename
Specifies the domain name suffix common to all of the file server machines named by the -server argument. For discussion of this argument's effects, see Using the -basename argument to Specify a Domain Name.
Do not include the period that separates the domain suffix from the initial part of the machine name, but do include any periods that occur within the suffix itself. (For example, in the ABC Corporation cell, the proper value is abc.com, not .abc.com.)
- -frequency
Sets the frequency, in seconds, of the scout program's probes to File Server processes. Specify an integer greater than 0 (zero). The default is 60 seconds.
- -host
Displays the name of the machine that is running the scout program in the display window's banner line. By default, no machine name is displayed.
- -attention
Defines the threshold value at which to highlight one or more statistics. You can provide the pairs of statistic and threshold in any order, separating each pair and the parts of each pair with one or more spaces. The following list defines the syntax for each statistic.
- conn connections
Highlights the value in the Conn (first) column when the number of connections that the File Server has open to client machines exceeds the connections value. The highlighting deactivates when the value goes back below the threshold. There is no default threshold.
- fetch fetch_RPCs
Highlights the value in the Fetch (second) column when the number of fetch RPCs that clients have made to the File Server process exceeds the fetch_RPCs value. The highlighting deactivates only when the File Server process restarts, at which time the value returns to zero. There is no default threshold.
- store store_RPCs
Highlights the value in the Store (third) column when the number of store RPCs that clients have made to the File Server process exceeds the store_RPCs value. The highlighting deactivates only when the File Server process restarts, at which time the value returns to zero. There is no default threshold.
- ws active_clients
Highlights the value in the Ws (fourth) column when the number of active client machines (those that have contacted the File Server in the last 15 minutes) exceeds the active_clients value. The highlighting deactivates when the value goes back below the threshold. There is no default threshold.
- disk percent_full % or disk min_blocks
Highlights the value for a partition in the Disk attn (sixth) column when either the amount of disk space used exceeds the percentage indicated by thepercent_full value, or the number of free KB blocks is less than the min_blocks value. The highlighting deactivates when the value goes back below the percent_full threshold or above the min_blocks threshold.
The value you specify appears in the header of the sixth column following the string Disk attn. The default threshold is 95% full.
Acceptable values for percent_full are the integers from the range 0 (zero) to 99, and you must include the percent sign to distinguish this statistic from a min_blocks value..
The following example sets the threshold for the Conn column to 100, for the Ws column to 50, and for the Disk attn column to 75%. There is no threshold for the Fetch and Store columns.
-attention conn 100 ws 50 disk 75%
The following example has the same affect as the previous one except that it sets the threshold for the Disk attn column to 5000 free KB blocks:
-attention disk 5000 ws 50 conn 100
- -debug
Enables debugging output and directs it into the specified file. Partial pathnames are interpreted relative to the current working directory. By default, no debugging output is produced.
To stop the scout program
Enter Ctrl-c in the display window. This is the proper interrupt signal even if the general interrupt signal in your environment is different.
Example Commands and Displays
This section presents examples of the scout program, combining different arguments and illustrating the screen displays that result.
In the first example, an administrator in the ABC Corporation issues the scout command without providing any optional arguments or flags. She includes the -server argument because she is providing multiple machine names. She chooses to specify on the initial part of each machine's name even though she has not used the -basename argument, relying on the cell's name service to obtain the fully-qualified name that the scout program requires for establishing a connection.
% scout -server fs1 fs2
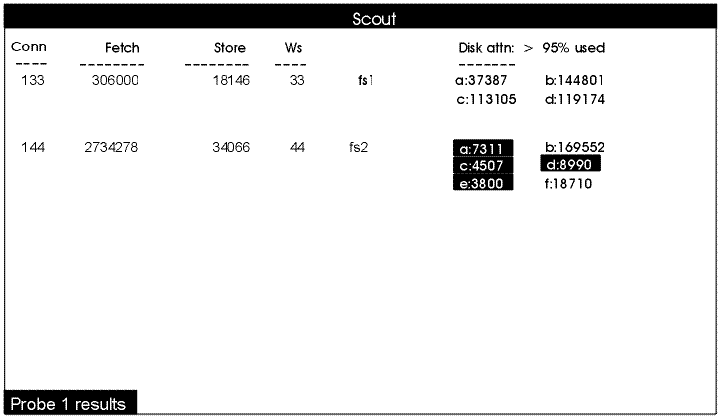
Figure 2 depicts the resulting display. Notice first that the machine names in the fifth (unlabeled) column appear in the format the administrator used on the command line. Now consider the second line in the display region, where the machine name fs2 appears in the fifth column. The Conn and Ws columns together show that machine fs2 has 144 RPC connections open to 44 client machines, demonstrating that multiple connections per client machine are possible. The Fetch column shows that client machines have made 2,734,278 fetch RPCs to machine fs2 since the File Server process last started and the Store column shows that they have made 34,066 store RPCs.
Six partition entries appear in the Disk attn column, marked a through f (for /vicepa through /vicepf). They appear on three lines in two subcolumns because of the width of the window; if the window is wider, there are more subcolumns. Four of the partition entries (a, c, d, and e) appear in reverse video to indicate that they are more than 95% full (the threshold value that appears in the Disk attn header).
In the second example, the administrator uses more of the scout program's optional arguments.
She provides the machine names in the same form as in Example 1, but this time she also uses the -basename argument to specify their domain name suffix, abc.com. This implies that the scout program does not need the name service to expand the names to fully-qualified hostnames, but the name service still converts the hostnames to IP addresses.
She uses the -host flag to display in the banner line the name of the client machine where the scout program is running.
She uses the -frequency argument to changes the probing frequency from its default of once per minute to once every five seconds.
She uses the -attention argument to changes the highlighting threshold for partitions to a 5000 KB minimum rather than the default of 95% full.
% scout -server fs1 fs2 -basename abc.com -host -frequency 5 -attention disk 5000
The use of optional arguments results in several differences between Figure 3 and Figure 2. First, because the -host flag is included, the banner line displays the name of the machine running the scout process as [client52] along with the basename abc.com specified with the -basename argument.
Another difference is that two rather than four of machine fs2's partitions appear in reverse video, even though their values are almost the same as in Figure 2. This is because the administrator changed the highlight threshold to a 5000 block minimum, as also reflected in the Disk attn column's header. And while machine fs2's partitions /vicepa and /vicepd are still 95% full, they have more than 5000 free blocks left; partitions /vicepc and /vicepe are highlighted because they have fewer than 5000 blocks free.
Note also the result of changing the probe frequency, reflected in the probe reporting line at the bottom left corner of the display. Both this example and the previous one represent a time lapse of one minute after the administrator issues the scout command. In this example, however, the scout program has probed the File Server processes 12 times as opposed to once

In Figure 4, an administrator in the State University cell monitors three of that cell's file server machines. He uses the -basename argument to specify the stateu.edu domain name.
% scout -server server2 server3 server4 -basename stateu.edu
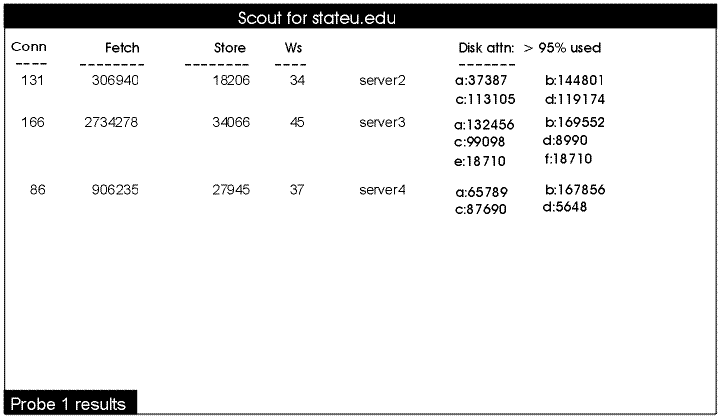
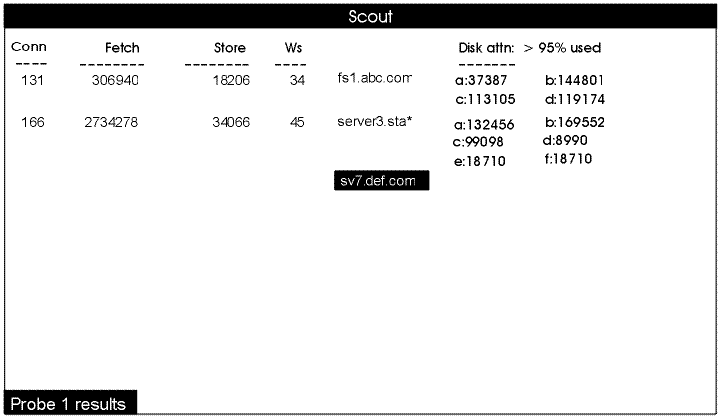
Figure 5 illustrates three of the scout program's features. First, you can monitor file server machines from different cells in a single display: fs1.abc.com, server3.stateu.edu, and sv7.def.com. Because the machines belong to different cells, it is not possible to provide the -basename argument.
Second, it illustrates how the display must truncate machine names that do not fit in the fifth column, using an asterisk at the end of the name to show that it is shortened.
Third, it illustrates what happens when the scout process cannot reach a File Server process, in this case the one on the machine sv7.def.com: it highlights the machine name and blanks out the values in the other columns.
Using the fstrace Command Suite
This section describes the fstrace commands that system administrators employ to trace Cache Manager activity for debugging purposes. It assumes the reader is familiar with the Cache Manager concepts described in Administering Client Machines and the Cache Manager.
The fstrace command suite monitors the internal activity of the Cache Manager and enables you to record, or trace, its operations in detail. The operations, which are termed events, comprise the cm event set. Examples of cm events are fetching files and looking up information for a listing of files and subdirectories using the UNIX ls command.
Following are the fstrace commands and their respective functions:
The fstrace apropos command provides a short description of commands.
The fstrace clear command clears the trace log.
The fstrace dump command dumps the contents of the trace log.
The fstrace help command provides a description and syntax for commands.
The fstrace lslog command lists information about the trace log.
The fstrace lsset command lists information about the event set.
The fstrace setlog command changes the size of the trace log.
The fstrace setset command sets the state of the event set.
About the fstrace Command Suite
The fstrace command suite replaces and greatly expands the functionality formerly provided by the fs debug command. Its intended use is to aid in diagnosis of specific Cache Manager problems, such as client machine hangs, cache consistency problems, clock synchronization errors, and failures to access a volume or AFS file. Therefore, it is best not to keep fstrace logging enabled at all times, unlike the logging for AFS server processes.
Most of the messages in the trace log correspond to low-level Cache Manager operations. It is likely that only personnel familiar with the AFS source code can interpret them. If you have an AFS source license, you can attempt to interpret the trace yourself, or work with the AFS Product Support group to resolve the underlying problems. If you do not have an AFS source license, it is probably more efficient to contact the AFS Product Support group immediately in case of problems. They can instruct you to activate fstrace tracing if appropriate.
The log can grow in size very quickly; this can use valuable disk space if you are writing to a file in the local file space. Additionally, if the size of the log becomes too large, it can become difficult to parse the results for pertinent information.
When AFS tracing is enabled, each time a cm event occurs, a message is written to the trace log, cmfx. To diagnose a problem, read the output of the trace log and analyze the operations executed by the Cache Manager. The default size of the trace log is 60 KB, but you can increase or decrease it.
To use the fstrace command suite, you must first enable tracing and reserve, or allocate, space for the trace log with the fstrace setset command. With this command, you can set the cm event set to one of three states to enable or disable tracing for the event set and to allocate or deallocate space for the trace log in the kernel:
- active
Enables tracing for the event set and allocates space for the trace log.
- inactive
Temporarily disables tracing for the event set; however, the event set continues to allocate space occupied by the log to which it sends data.
- dormant
Disables tracing for the event set; furthermore, the event set releases the space occupied by the log to which it sends data. When the cm event set that sends data to the cmfx trace log is in this state, the space allocated for that log is freed or deallocated.
Both event sets and trace logs can be designated as persistent, which prevents accidental resetting of an event set's state or clearing of a trace log. The designation is made as the kernel is compiled and cannot be changed.
If an event set such as cm is persistent, you can change its state only by including the -set argument to the fstrace setset command. (That is, you cannot change its state along with the state of all other event sets by issuing the fstrace setset command with no arguments.) Similarly, if a trace log such as cmfx is persistent, you can clear it only by including either the -set or -log argument to the fstrace clear command (you cannot clear it along with all other trace logs by issuing the fstrace clear command with no arguments.)
When a problem occurs, set the cm event set to active using the fstrace setset command. When tracing is enabled on a busy AFS client, the volume of events being recorded is significant; therefore, when you are diagnosing problems, restrict AFS activity as much as possible to minimize the amount of extraneous tracing in the log. Because tracing can have a negative impact on system performance, leave cm tracing in the dormant state when you are not diagnosing problems.
If a problem is reproducible, clear the cmfx trace log with the fstrace clear command and reproduce the problem. If the problem is not easily reproduced, keep the state of the event set active until the problem recurs.
To view the contents of the trace log and analyze the cm events, use the fstrace dump command to copy the content lines of the trace log to standard output (stdout) or to a file.
Note: If a particular command or process is causing problems, determine its process id (PID). Search the output of the fstrace dump command for the PID to find only those lines associated with the problem.
Requirements for Using the fstrace Command Suite
Except for the fstrace help and fstrace apropos commands, which require no privilege, issuing the fstrace commands requires that the issuer be logged in as the local superuser root on the local client machine. Before issuing an fstrace command, verify that you have the necessary privilege.
The Cache Manager catalog must be in place so that logging can occur. The fstrace command suite uses the standard UNIX catalog utilities. The default location is /usr/vice/etc/C/afszcm.cat. It can be placed in another directory by placing the file elsewhere and using the proper NLSPATH and LANG environment variables.
Using fstrace Commands Effectively
To use fstrace commands most effectively, configure them as indicated:
Store the fstrace binary in a local disk directory.
When you dump the fstrace log to a file, direct it to one on the local disk.
The trace can grow large in just a few minutes. Before attempting to dump the log to a local file, verify that you have enough room. Be particularly careful if you are using disk quotas on partitions in the local file system.
Attempt to limit Cache Manager activity on the AFS client machine other than the problem operation. This reduces the amount of extraneous data in the trace.
Activate the fstrace log for the shortest possibly period of time. If possible activate the trace immediately before performing the problem operation, deactivate it as soon as the operation completes, and dump the trace log to a file immediately.
If possible, obtain UNIX process ID (PID) of the command or program that initiates the problematic operation. This enables the person analyzing the trace log to search it for messages associated with the PID.
Activating the Trace Log
To start Cache Manager tracing on an AFS client machine, you must first configure
The cmfx kernel trace log using the fstrace setlog command
The cm event set using the fstrace setset command
The fstrace setlog command sets the size of the cmfx kernel trace log in kilobytes. The trace log occupies 60 kilobytes of kernel by default. If the trace log already exists, it is cleared when this command is issued and a new log of the given size is created. Otherwise, a new log of the desired size is created.
The fstrace setset command sets the state of the cm kernel event set. The state of the cm event set determines whether information on the events in that event set is logged.
After establishing kernel tracing on the AFS client machine, you can check the state of the event set and the size of the kernel buffer allocated for the trace log. To display information about the state of the cm event set, issue the fstrace lsset command. To display information about the cmfx trace log, use the fstrace lslog command. See the instructions in Displaying the State of a Trace Log or Event Set.
To configure the trace log
Become the local superuser root on the machine, if you are not already, by issuing the su command.
% su root Password: <root_password>Issue the fstrace setlog command to set the size of the cmfx kernel trace log.
# fstrace setlog [-log <log_name>+] -buffersize <1-kilobyte_units>
The following example sets the size of the cmfx trace log to 80 KB.
# fstrace setlog cmfx 80
To set the event set
Become the local superuser root on the machine, if you are not already, by issuing the su command.
% su root Password: <root_password>Issue the fstrace setset command to set the state of event sets.
% fstrace setset [-set <set_name>+] [-active] [-inactive] \ [-dormant]
The following example activates the cm event set.
# fstrace setset cm -active
Displaying the State of a Trace Log or Event Set
An event set must be in the active state to be included in the trace log. To display an event set's state, use the fstrace lsset command. To set its state, issue the fstrace setset command as described in To set the event set.
To display size and allocation information for the trace log, issue the fstrace lslogcommand with the -long argument.
To display the state of an event set
Become the local superuser root on the machine, if you are not already, by issuing the su command.
% su root Password: <root_password>Issue the fstrace lsset command to display the available event set and its state.
# fstrace lsset [-set <set_name>+]
The following example displays the event set and its state on the local machine.
# fstrace lsset cm
Available sets:
cm active
The output from this command lists the event set and its states. The three event states for the cm event set are:
- active
Tracing is enabled.
- inactive
Tracing is disabled, but space is still allocated for the corresponding trace log (cmfx).
- dormant
Tracing is disabled, and space is no longer allocated for the corresponding trace log (cmfx).Disables tracing for the event set.
To display the log size
Become the local superuser root on the machine, if you are not already, by issuing the su command.
% su root Password: <root_password>Issue the fstrace lslog command to display information about the kernel trace log.
# fstrace lslog [-set <set_name>+] [-log <log_name>] [-long]
The following example uses the -long flag to display additional information about the cmfx trace log.
# fstrace lslog cmfx -long
Available logs:
cmfx : 60 kbytes (allocated)
The output from this command lists information on the trace log. When issued without the -long flag, the fstrace lslog command lists only the name of the log. When issued with the -long flag, the fstrace lslog command lists the log, the size of the log in kilobytes, and the allocation state of the log.
There are two allocation states for the kernel trace log:
- allocated
Space is reserved for the log in the kernel. This indicates that the event set that writes to this log is either active (tracing is enabled for the event set) or inactive (tracing is temporarily disabled for the event set); however, the event set continues to reserve space occupied by the log to which it sends data.
- unallocated
Space is not reserved for the log in the kernel. This indicates that the event set that writes to this log is dormant (tracing is disabled for the event set); furthermore, the event set releases the space occupied by the log to which it sends data.
Dumping and Clearing the Trace Log
After the Cache Manager operation you want to trace is complete, use the fstrace dump command to dump the trace log to the standard output stream or to the file named by the -file argument. Or, to dump the trace log continuously, use the -follow argument (combine it with the -file argument if desired). To halt continuous dumping, press an interrupt signal such as <Ctrl-c>.
To clear a trace log when you no longer need the data in it, issue the fstrace clear command. (The fstrace setlog command also clears an existing trace log automatically when you use it to change the log's size.)
To dump the contents of a trace log
Become the local superuser root on the machine, if you are not already, by issuing the su command.
% su root Password: <root_password>Issue the fstrace dump command to dump trace logs.
# fstrace dump [-set <set_name>+] [-follow <log_name>] \ [-file <output_filename>] \ [-sleep <seconds_between_reads>]
At the beginning of the output of each dump is a header specifying the date and time at which the dump began. The number of logs being dumped is also displayed if the -follow argument is not specified. The header appears as follows:
AFS Trace Dump -- Date: date time Found n logs.
where date is the starting date of the trace log dump, time is the starting time of the trace log dump, and n specifies the number of logs found by the fstrace dump command.
The following is an example of trace log dump header:
AFS Trace Dump -- Date: Fri Apr 16 10:44:38 1999 Found 1 logs.
The contents of the log follow the header and are comprised of messages written to the log from an active event set. The messages written to the log contain the following three components:
The timestamp associated with the message (number of seconds from an arbitrary start point)
The process ID or thread ID associated with the message
The message itself
A trace log message is formatted as follows:
time timestamp, pid pid:event message
where timestamp is the number of seconds from an arbitrary start point, pid is the process ID number of the Cache Manager event, and event message is the Cache Manager event which corresponds with a function in the AFS source code.
The following is an example of a dumped trace log message:
time 749.641274, pid 3002:Returning code 2 from 19
For the messages in the trace log to be most readable, the Cache Manager catalog file needs to be installed on the local disk of the client machine; the conventional location is /usr/vice/etc/C/afszcm.cat. Log messages that begin with the string raw op, like the following, indicate that the catalog is not installed.
raw op 232c, time 511.916288, pid 0 p0:Fri Apr 16 10:36:31 1999
Every 1024 seconds, a current time message is written to each log. This message has the following format:
time timestamp, pid pid: Current time: unix_time
where timestamp is the number of seconds from an arbitrary start point, pid is the process ID number, and unix_time is the standard time format since January 1, 1970.
The current time message can be used to determine the actual time associated with each log message. Determine the actual time as follows:
Locate the log message whose actual time you want to determine.
Search backward through the dump record until you come to a current time message.
If the current time message's timestamp is smaller than the log message's timestamp, subtract the former from the latter. If the current time message's timestamp is larger than the log message's timestamp, add 1024 to the latter and subtract the former from the result.
Add the resulting number to the current time message's unix_time to determine the log message's actual time.
Because log data is stored in a finite, circular buffer, some of the data can be overwritten before being read. If this happens, the following message appears at the appropriate place in the dump:
Log wrapped; data missing.
Note: If this message appears in the middle of a dump, which can happen under a heavy work load, it indicates that not all of the log data is being written to the log or some data is being overwritten. Increasing the size of the log with the fstrace setlog command can alleviate this problem.
To clear the contents of a trace log
Become the local superuser root on the machine, if you are not already, by issuing the su command.
% su root Password: <root_password>Issue the fstrace clear command to clear logs by log name or by event set.
# fstrace clear [-set <set_name>+] [-log <log_name>+]
The following example clears the cmfx log used by the cm event set on the local machine.
# fstrace clear cm
The following example also clears the cmfx log on the local machine.
# fstrace clear cmfx
Examples of fstrace Commands
This section contains an extensive example of the use of the fstrace command suite, which is useful for gathering a detailed trace of Cache Manager activity when you are working with AFS Product Support to diagnose a problem. The Product Support representative can guide you in choosing appropriate parameter settings for the trace.
Before starting the kernel trace log, try to isolate the Cache Manager on the AFS client machine that is experiencing the problem accessing the file. If necessary, instruct users to move to another machine so as to minimize the Cache Manager activity on this machine. To minimize the amount of unrelated AFS activity recorded in the trace log, place both the fstrace binary and the dump file must reside on the local disk, not in AFS. You must be logged in as the local superuser root to issue fstrace commands.
Before starting a kernel trace, issue the fstrace lsset command to check the state of the cm event set.
# fstrace lsset cm
If tracing has not been enabled previously or if tracing has been turned off on the client machine, the following output is displayed:
Available sets: cm inactive
If tracing has been turned off and kernel memory is not allocated for the trace log on the client machine, the following output is displayed:
Available sets: cm inactive (dormant)
If the current state of the cm event set is inactive or inactive (dormant), turn on kernel tracing by issuing the fstrace setset command with the -active flag.
# fstrace setset cm -active
If tracing is enabled currently on the client machine, the following output is displayed:
Available sets: cm active
If tracing is enabled currently, you do not need to use the fstrace setset command. Do issue the fstrace clear command to clear the contents of any existing trace log, removing prior traces that are not related to the current problem.
# fstrace clear cm
After checking on the state of the event set, issue the fstrace lslog command with the -long flag to check the current state and size of the kernel trace log .
# fstrace lslog cmfx -long
If tracing has not been enabled previously or the cm event set was set to active or inactive previously, output similar to the following is displayed:
Available logs: cmfx : 60 kbytes (allocated)
The fstrace tracing utility allocates 60 kilobytes of memory to the trace log by default. You can increase or decrease the amount of memory allocated to the kernel trace log by setting it with the fstrace setlog command. The number specified with the -buffersize argument represents the number of kilobytes allocated to the kernel trace log. If you increase the size of the kernel trace log to 100 kilobytes, issue the following command.
# fstrace setlog cmfx 100
After ensuring that the kernel trace log is configured for your needs, you can set up a file into which you can dump the kernel trace log. For example, create a dump file with the name cmfx.dump.file.1 using the following fstrace dump command. Issue the command as a continuous process by adding the -follow and -sleep arguments. Setting the -sleep argument to 10 dumps output from the kernel trace log to the file every 10 seconds.
# fstrace dump -follow cmfx -file cmfx.dump.file.1 -sleep 10 AFS Trace Dump - Date: Fri Apr 16 10:54:57 1999 Found 1 logs. time 32.965783, pid 0: Fri Apr 16 10:45:52 1999 time 32.965783, pid 33657: Close 0x5c39ed8 flags 0x20 time 32.965897, pid 33657: Gn_close vp 0x5c39ed8 flags 0x20 (returns 0x0) time 35.159854, pid 10891: Breaking callback for 5bd95e4 states 1024 (volume 0) time 35.407081, pid 10891: Breaking callback for 5c0fadc states 1024 (volume 0) . . . . . . time 71.440456, pid 33658: Lookup adp 0x5bbdcf0 name g3oCKs fid (756 4fb7e:588d240.2ff978a8.6) time 71.440569, pid 33658: Returning code 2 from 19 time 71.440619, pid 33658: Gn_lookup vp 0x5bbdcf0 name g3oCKs (returns 0x2) time 71.464989, pid 38267: Gn_open vp 0x5bbd000 flags 0x0 (returns 0x 0) AFS Trace Dump - Completed
Using the afsmonitor Program
The afsmonitor program enables you to monitor the status and performance of specified File Server and Cache Manager processes by gathering statistical information. Among its other uses, the afsmonitor program can be used to fine-tune Cache Manager configuration and load balance File Servers.
The afsmonitor program enables you to perform the following tasks.
Monitor any number of File Server and Cache Manager processes on any number of machines (in both local and foreign cells) from a single location.
Set threshold values for any monitored statistic. When the value of a statistic exceeds the threshold, the afsmonitor program highlights it to draw your attention. You can set threshold levels that apply to every machine or only some.
Invoke programs or scripts automatically when a statistic exceeds its threshold.
Requirements for running the afsmonitor program
The following software must be accessible to a machine where the afsmonitor program is running:
The AFS xstat libraries, which the afsmonitor program uses to gather data
The curses graphics package, which most UNIX distributions provide as a standard utility
The afsmonitor screens format successfully both on so-called dumb terminals and in windowing systems that emulate terminals. For the output to looks its best, the display environment needs to support reverse video and cursor addressing. Set the TERM environment variable to the correct terminal type, or to a value that has characteristics similar to the actual terminal type. The display window or terminal must be at least 80 columns wide and 12 lines long.
The afsmonitor program must run in the foreground, and in its own separate, dedicated window or terminal. The window or terminal is unavailable for any other activity as long as the afsmonitor program is running. Any number of instances of the afsmonitor program can run on a single machine, as long as each instance runs in its own dedicated window or terminal. Note that it can take up to three minutes to start an additional instance.
No privilege is required to run the afsmonitor program. By convention, it is installed in the /usr/afsws/bin directory, and anyone who can access the directory can monitor File Servers and Cache Managers. The probes through which the afsmonitor program collects statistics do not constitute a significant burden on the File Server or Cache Manager unless hundreds of people are running the program. If you wish to restrict its use, place the binary file in a directory available only to authorized users.
The afsmonitor Output Screens
The afsmonitor program displays its data on three screens:
System Overview: This screen appears automatically when the afsmonitor program initializes. It summarizes separately for File Servers and Cache Managers the number of machines being monitored and how many of them have alerts (statistics that have exceeded their thresholds). It then lists the hostname and number of alerts for each machine being monitored, indicating if appropriate that a process failed to respond to the last probe.
File Server: This screen displays File Server statistics for each file server machine being monitored. It highlights statistics that have exceeded their thresholds, and identifies machines that failed to respond to the last probe.
Cache Managers: This screen displays Cache Manager statistics for each client machine being monitored. It highlights statistics that have exceeded their thresholds, and identifies machines that failed to respond to the last probe.
Fields at the corners of every screen display the following information:
In the top left corner, the program name and version number.
In the top right corner, the screen name, current and total page numbers, and current and total column numbers. The page number (for example, p. 1 of 3) indicates the index of the current page and the total number of (vertical) pages over which data is displayed. The column number (for example, c. 1 of 235) indicates the index of the current leftmost column and the total number of columns in which data appears. (The symbol >>> indicates that there is additional data to the right; the symbol <<< indicates that there is additional data to the left.)
In the bottom left corner, a list of the available commands. Enter the first letter in the command name to run that command. Only the currently possible options appear; for example, if there is only one page of data, the next and prev commands, which scroll the screen up and down respectively, do not appear. For descriptions of the commands, see the following section about navigating the display screens.
In the bottom right corner, the probes field reports how many times the program has probed File Servers (fs), Cache Managers (cm), or both. The counts for File Servers and Cache Managers can differ. The freq field reports how often the program sends probes.
Navigating the afsmonitor Display Screens
As noted, the lower left hand corner of every display screen displays the names of the commands currently available for moving to alternate screens, which can either be a different type or display more statistics or machines of the current type. To execute a command, press the lowercase version of the first letter in its name. Some commands also have an uppercase version that has a somewhat different effect, as indicated in the following list.
- cm
Switches to the Cache Managers screen. Available only on the System Overview and File Servers screens.
- fs
Switches to the File Servers screen. Available only on the System Overview and the Cache Managers screens.
- left
Scrolls horizontally to the left, to access the data columns situated to the left of the current set. Available when the <<< symbol appears at the top left of the screen. Press uppercase L to scroll horizontally all the way to the left (to display the first set of data columns).
- next
Scrolls down vertically to the next page of machine names. Available when there are two or more pages of machines and the final page is not currently displayed. Press uppercase N to scroll to the final page.
- oview
Switches to the System Overview screen. Available only on the Cache Managers and File Servers screens.
- prev
Scrolls up vertically to the previous page of machine names. Available when there are two or more pages of machines and the first page is not currently displayed. Press uppercase N to scroll to the first page.
- right
Scrolls horizontally to the right, to access the data columns situated to the right of the current set. This command is available when the >>> symbol appears at the upper right of the screen. Press uppercase R to scroll horizontally all the way to the right (to display the final set of data columns).
The System Overview Screen
The System Overview screen appears automatically as the afsmonitor program initializes. This screen displays the status of as many File Server and Cache Manager processes as can fit in the current window; scroll down to access additional information.
The information on this screen is split into File Server information on the left and Cache Manager information on the right. The header for each grouping reports two pieces of information:
The number of machines on which the program is monitoring the indicated process
The number of alerts and the number of machines affected by them (an alert means that a statistic has exceeded its threshold or a process failed to respond to the last probe)
A list of the machines being monitored follows. If there are any alerts on a machine, the number of them appears in square brackets to the left of the hostname. If a process failed to respond to the last probe, the letters PF (probe failure) appear in square brackets to the left of the hostname.
The following graphic is an example System Overview screen. The afsmonitor program is monitoring six File Servers and seven Cache Managers. The File Server process on host fs1.abc.com and the Cache Manager on host cli33.abc.com are each marked [ 1] to indicate that one threshold value is exceeded. The [PF] marker on host fs6.abc.com indicates that its File Server process did not respond to the last probe.

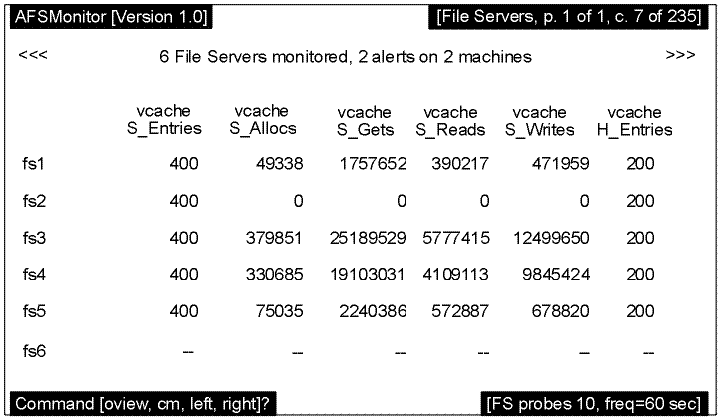
The File Servers Screen
The File Servers screen displays the values collected at the most recent probe for File Server statistics.
A summary line at the top of the screen (just below the standard program version and screen title blocks) specifies the number of monitored File Servers, the number of alerts, and the number of machines affected by the alerts.
The first column always displays the hostnames of the machines running the monitored File Servers.
To the right of the hostname column appear as many columns of statistics as can fit within the current width of the display screen or window; each column requires space for 10 characters. The name of the statistic appears at the top of each column. If the File Server on a machine did not respond to the most recent probe, a pair of dashes (--) appears in each column. If a value exceeds its configured threshold, it is highlighted in reverse video. If a value is too large to fit into the allotted column width, it overflows into the next row in the same column.
For a list of the available File Server statistics, see Appendix C, The afsmonitor Program Statistics.
The following graphic depicts the File Servers screen that follows the System Overview Screen example previously discussed; however, one additional server probe has been completed. In this example, the File Server process on fs1 has exceeded the configured threshold for the number of performance calls received (the numPerfCalls statistic), and that field appears in reverse video. Host fs6 did not respond to Probe 10, so dashes appear in all fields.
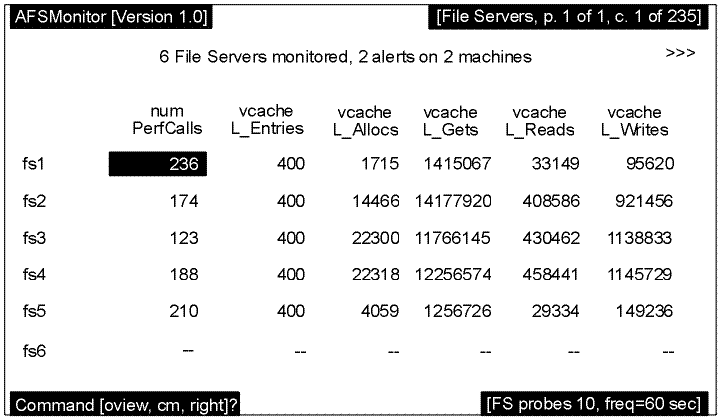
Both the File Servers and Cache Managers screen (discussed in the following section) can display hundreds of columns of data and are therefore designed to scroll left and right. In the preceding graphic, the screen displays the leftmost screen and the screen title block shows that column 1 of 235 is displayed. The appearance of the >>> symbol in the upper right hand corner of the screen and the right command in the command block indicate that additional data is available by scrolling right. (For information on the available statistics, see Appendix C, The afsmonitor Program Statistics.)
If the right command is executed, the screen looks something like the following example. Note that the horizontal scroll symbols now point both to the left (<<<) and to the right (>>>) and both the left and right commands appear, indicating that additional data is available by scrolling both left and right.
The Cache Managers Screen
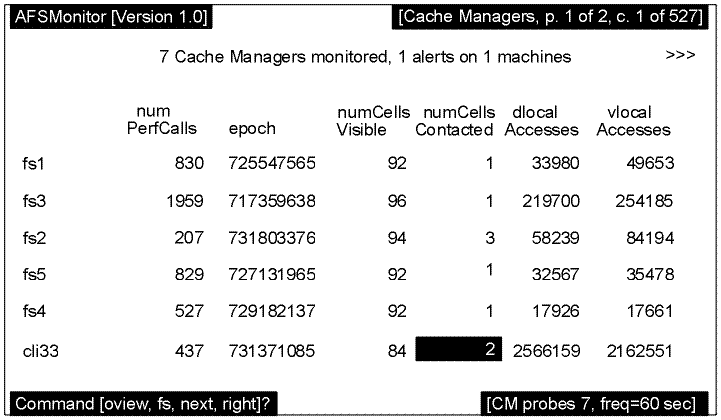
The Cache Managers screen displays the values collected at the most recent probe for Cache Manager statistics.
A summary line at the top of the screen (just below the standard program version and screen title blocks) specifies the number of monitored Cache Managers, the number of alerts, and the number of machines affected by the alerts.
The first column always displays the hostnames of the machines running the monitored Cache Managers.
To the right of the hostname column appear as many columns of statistics as can fit within the current width of the display screen or window; each column requires space for 10 characters. The name of the statistic appears at the top of each column. If the Cache Manager on a machine did not respond to the most recent probe, a pair of dashes (--) appears in each column. If a value exceeds its configured threshold, it is highlighted in reverse video. If a value is too large to fit into the allotted column width, it overflows into the next row in the same column.
For a list of the available Cache Manager statistics, see Appendix C, The afsmonitor Program Statistics.
The following graphic depicts a Cache Managers screen that follows the System Overview Screen previously discussed. In the example, the Cache Manager process on host cli33 has exceeded the configured threshold for the number of cells it can contact (the numCellsContacted statistic), so that field appears in reverse video.
Configuring the afsmonitor Program
To customize the afsmonitor program, create an ASCII-format configuration file and use the -config argument to name it. You can specify the following in the configuration file:
The File Servers, Cache Managers, or both to monitor.
The statistics to display. By default, the display includes 271 statistics for File Servers and 570 statistics for Cache Managers. For information on the available statistics, see Appendix C, The afsmonitor Program Statistics.
The threshold values to set for statistics and a script or program to execute if a threshold is exceeded. By default, no threshold values are defined and no scripts or programs are executed.
The following list describes the instructions that can appear in the configuration file:
- cm hostname
Names a client machine for which to display Cache Manager statistics. The order of cm lines in the file determines the order in which client machines appear from top to bottom on the System Overview and Cache Managers output screens.
- fs hostname
Names a file server machine for which to display File Server statistics. The order of fs lines in the file determines the order in which file server machines appear from top to bottom on the System Overview and File Servers output screens.
- thresh fs | cm field_name thresh_val [cmd_to_run] [arg1] . . . [argn]
Assigns the threshold value thresh_val to the statistic field_name, for either a File Server statistic (fs) or a Cache Manager statistic (cm). The optional cmd_to_execute field names a binary or script to execute each time the value of the statistic changes from being below thresh_val to being at or above thresh_val. A change between two values that both exceed thresh_val does not retrigger the binary or script. The optional arg1 through argn fields are additional values that the afsmonitor program passes as arguments to the cmd_to_execute command. If any of them include one or more spaces, enclose the entire field in double quotes.
The parameters fs, cm, field_name, threshold_val, and arg1 through argn correspond to the values with the same name on the thresh line. The host_name parameter identifies the file server or client machine where the statistic has crossed the threshold, and the actual_val parameter is the actual value of field_name that equals or exceeds the threshold value.
Use the thresh line to set either a global threshold, which applies to all file server machines listed on fs lines or client machines listed on cm lines in the configuration file, or a machine-specific threshold, which applies to only one file server or client machine.
To set a global threshold, place the thresh line before any of the fs or cm lines in the file.
To set a machine-specific threshold, place the thresh line below the corresponding fs or cm line, and above any other fs or cm lines. A machine-specific threshold value always overrides the corresponding global threshold, if set. Do not place a thresh fs line directly after a cm line or a thresh cm line directly after a fs line.
- show fs | cm field/group/section
Specifies which individual statistic, group of statistics, or section of statistics to display on the File Servers screen (fs) or Cache Managers screen (cm) and the order in which to display them. The appendix of afsmonitor statistics in the IBM AFS Administration Guide specifies the group and section to which each statistic belongs. Include as many show lines as necessary to customize the screen display as desired, and place them anywhere in the file. The top-to-bottom order of the show lines in the configuration file determines the left-to-right order in which the statistics appear on the corresponding screen.
If there are no show lines in the configuration file, then the screens display all statistics for both Cache Managers and File Servers. Similarly, if there are no show fs lines, the File Servers screen displays all file server statistics, and if there are no show cm lines, the Cache Managers screen displays all client statistics.
- # comments
Precedes a line of text that the afsmonitor program ignores because of the initial number (#) sign, which must appear in the very first column of the line.
For a list of the values that can appear in the field/group/section field of a show instruction, see Appendix C, The afsmonitor Program Statistics.)
The following example illustrates a possible configuration file:
thresh cm dlocalAccesses 1000000 thresh cm dremoteAccesses 500000 handleDRemote thresh fs rx_maxRtt_Usec 1000 cm client5 cm client33 cm client14 thresh cm dlocalAccesses 2000000 thresh cm vcacheMisses 10000 cm client2 fs fs3 fs fs9 fs fs5 fs fs10 show cm numCellsContacted show cm dlocalAccesses show cm dremoteAccesses show cm vcacheMisses show cm Auth_Stats_group
Since the first three thresh instructions appear before any fs or cm instructions, they set global threshold values:
All Cache Manager process in this file use 1000000 as the threshold for the dlocalAccesses statistic (except for the machine client2 which uses an overriding value of 2000000.)
All Cache Manager processes in this file use 500000 as the threshold value for the dremoteAccesses statistic; if that value is exceeded, the script handleDRemote is invoked.
All File Server processes in this file use 1000 as the threshold value for the rx_maxRtt_Usec statistic.
The four cm instructions monitor the Cache Manager on the machines client5, client33, client14, and client2. The first three use all of the global threshold values.
The Cache Manager on client2 uses the global threshold value for the dremoteAccesses statistic, but a different one for the dlocalAccesses statistic. Furthermore, client22 is the only Cache Manager that uses the threshold set for the vcacheMisses statistic.
The fs instructions monitor the File Server on the machines fs3, fs9, fs5, and fs10. They all use the global threshold for therx_maxRtt_Usec statistic.
Because there are no show fs instructions, the File Servers screen displays all File Server statistics. The Cache Managers screen displays only the statistics named in show cm instructions, ordering them from left to right. The Auth_Stats_group includes several statistics, all of which are displayed (curr_PAGs, curr_Records, curr_AuthRecords, curr_UnauthRecords, curr_MaxRecordsInPAG, curr_LongestChain, PAGCreations, TicketUpdates, HWM_PAGS, HWM_Records, HWM_MaxRecordsInPAG, and HWM_LongestChain).
Writing afsmonitor Statistics to a File
All of the statistical information collected and displayed by the afsmonitor program can be preserved by writing it to an output file. You can create an output file by using the -output argument when you startup the afsmonitor process. You can use the output file to track process performance over long periods of time and to apply post-processing techniques to further analyze system trends.
The afsmonitor program output file is a simple ASCII file that records the information reported by the File Server and Cache Manager screens. The output file has the following format:
time host_name CM|FS list_of_measured_values
and specifies the time at which the list_of_measured_values were gathered from the Cache Manager (CM) or File Server (FS) process housed on host_name. On those occasion where probes fail, the value -1 is reported instead of the list_of_measured_values.
This file format provides several advantages:
It can be viewed using a standard editor. If you intend to view this file frequently, use the -detailed flag with the -output argument. It formats the output file in a way that is easier to read.
It can be passed through filters to extract desired information using the standard set of UNIX tools.
It is suitable for long term storage of the afsmonitor program output.
To start the afsmonitor Program
Open a separate command shell window or use a dedicated terminal for each instance of the afsmonitor program. This window or terminal must be devoted to the exclusive use of the afsmonitor process because the command cannot be run in the background.
Initialize the afsmonitor program. The message afsmonitor Collecting Statistics..., followed by the appearance of the System Overview screen, confirms a successful start.
% afsmonitor [initcmd] [-config <configuration file>] \ [-frequency <poll frequency, in seconds>] \ [-output <storage file name>] [-detailed] \ [-debug <turn debugging output on to the named file>] \ [-fshosts <list of file servers to monitor>+] \ [-cmhosts <list of cache managers to monitor>+] afsmonitor Collecting Statistics...
where
- initcmd
Is an optional string that accommodates the command's use of the AFS command parser. It can be omitted and ignored.
- -config
Specifies the pathname of an afsmonitor configuration file, which lists the machines and statistics to monitor. Partial pathnames are interpreted relative to the current working directory. Provide either this argument or one or both of the -fshosts and -cmhosts arguments. You must use a configuration file to set thresholds or customize the screen display. For instructions on creating the configuration file, see Configuring the afsmonitor Program.
- -frequency
Specifies how often to probe the File Server and Cache Manager processes, as a number of seconds. Acceptable values range from 1 and 86400; the default value is 60. This frequency applies to both File Server and Cache Manager probes; however, File Server and Cache Manager probes are initiated and processed independent of each other. The actual interval between probes to a host is the probe frequency plus the time needed by all hosts to respond to the probe.
- -output
Specifies the name of an output file to which to write all of the statistical data. By default, no output file is created. For information on this file, see Writing afsmonitor Statistics to a File.
- -detailed
Formats the output file named by the -output argument to be more easily readable. The -output argument must be provided along with this flag.
- -fshosts
Identifies each File Server process to monitor by specifying the host it is running on. You can identify a host using either its complete Internet-style host name or an abbreviation acceptable to the cell's naming service. Combine this argument with the -cmhosts if you wish, but not the -config argument.
- -cmhosts
Identifies each Cache Manager process to monitor by specifying the host it is running on. You can identify a host using either its complete Internet-style host name or an abbreviation acceptable to the cell's naming service. Combine this argument with the -fshosts if you wish, but not the -config argument.
To stop the afsmonitor program
To exit an afsmonitor program session, Enter the <Ctrl-c> interrupt signal or an uppercase Q.
The xstat Data Collection Facility
The afsmonitor program uses the xstat data collection facility to gather and calculate the data that it (the afsmonitor program) then uses to perform its function. You can also use the xstat facility to create your own data display programs. If you do, keep the following in mind. The File Server considers any program calling its RPC routines to be a Cache Manager; therefore, any program calling the File Server interface directly must export the Cache Manager's callback interface. The calling program must be capable of emulating the necessary callback state, and it must respond to periodic keep-alive messages from the File Server. In addition, a calling program must be able to gather the collected data.
The xstat facility consists of two C language libraries available to user-level applications:
/usr/afsws/lib/afs/libxstat_fs.a exports calls that gather information from one or more running File Server processes.
/usr/afsws/lib/afs/libxstat_cm.a exports calls that collect information from one or more running Cache Managers.
The libraries allow the caller to register
A set of File Servers or Cache Managers to be examined.
The frequency with which the File Servers or Cache Managers are to be probed for data.
A user-specified routine to be called each time data is collected.
The libraries handle all of the lightweight processes, callback interactions, and timing issues associated with the data collection. The user needs only to process the data as it arrives.
The libxstat Libraries
The libxstat_fs.a and libxstat_cm.a libraries handle the callback requirements and other complications associated with the collection of data from File Servers and Cache Managers. The user provides only the means of accumulating the desired data. Each xstat library implements three routines:
Initialization (xstat_fs_Init and xstat_cm_Init) arranges the periodic collection and handling of data.
Immediate probe (xstat_fs_ForceProbeNow and xstat_cm_ForceProbeNow) forces the immediate collection of data, after which collection returns to its normal probe schedule.
Cleanup (xstat_fs_Cleanup and xstat_cm_Cleanup) terminates all connections and removes all traces of the data collection from memory.
The File Server and Cache Manager each define data collections that clients can fetch. A data collection is simply a related set of numbers that can be collected as a unit. For example, the File Server and Cache Manager each define profiling and performance data collections. The profiling collections maintain counts of the number of times internal functions are called within servers, allowing bottleneck analysis to be performed. The performance collections record, among other things, internal disk I/O statistics for a File Server and cache effectiveness figures for a Cache Manager, allowing for performance analysis.
For a copy of the detailed specification which provides much additional usage information about the xstat facility, its libraries, and the routines in the libraries, contact AFS Product Support.
Example xstat Commands
AFS comes with two low-level, example commands: xstat_fs_test and xstat_cm_test. The commands allow you to experiment with the xstat facility. They gather information and display the available data collections for a File Server or Cache Manager. They are intended merely to provide examples of the types of data that can be collected via xstat; they are not intended for use in the actual collection of data.
To use the example xstat_fs_test command
Issue the example xstat_fs_test command to test the routines in the libxstat_fs.a library and display the data collections associated with the File Server process. The command executes in the foreground.
% xstat_fs_test [initcmd] \ -fsname <File Server name(s) to monitor>+ \ -collID <Collection(s) to fetch>+ [-onceonly] \ [-frequency <poll frequency, in seconds>] \ [-period <data collection time, in minutes>] [-debug]
where
- xstat_fs_test
Must be typed in full.
- initcmd
Is an optional string that accommodates the command's use of the AFS command parser. It can be omitted and ignored.
- -fsname
Is the Internet host name of each file server machine on which to monitor the File Server process.
- -collID
Specifies each data collection to return. The indicated data collection defines the type and amount of data the command is to gather about the File Server. Data is returned in the form of a predefined data structure (refer to the specification documents referenced previously for more information about the data structures).
There are two acceptable values:
1 reports various internal performance statistics related to the File Server (for example, vnode cache entries and Rx protocol activity).
2 reports all of the internal performance statistics provided by the 1 setting, plus some additional, detailed performance figures about the File Server (for example, minimum, maximum, and cumulative statistics regarding File Server RPCs, how long they take to complete, and how many succeed).
- -onceonly
Directs the command to gather statistics just one time. Omit this option to have the command continue to probe the File Server for statistics every 30 seconds. If you omit this option, you can use the <Ctrl-c> interrupt signal to halt the command at any time.
- -frequency
Sets the frequency in seconds at which the program initiates probes to the File Server. If you omit this argument, the default is 30 seconds.
- -period
Sets how long the utility runs before exiting, as a number of minutes. If you omit this argument, the default is 10 minutes.
- -debug
Displays additional information as the command runs.
To use the example xstat_cm_test command
Issue the example xstat_cm_test command to test the routines in the libxstat_cm.a library and display the data collections associated with the Cache Manager. The command executes in the foreground.
% xstat_cm_test [initcmd] \ -cmname <Cache Manager name(s) to monitor>+ \ -collID <Collection(s) to fetch>+ \ [-onceonly] [-frequency <poll frequency, in seconds>] \ [-period <data collection time, in minutes>] [-debug]
where
- xstat_cm_test
Must be typed in full.
- initcmd
Is an optional string that accommodates the command's use of the AFS command parser. It can be omitted and ignored.
- -cmname
Is the host name of each client machine on which to monitor the Cache Manager.
- -collID
Specifies each data collection to return. The indicated data collection defines the type and amount of data the command is to gather about the Cache Manager. Data is returned in the form of a predefined data structure (refer to the specification documents referenced previously for more information about the data structures).
There are two acceptable values:
0 provides profiling information about the numbers of times different internal Cache Manager routines were called since the Cache manager was started.
1 reports various internal performance statistics related to the Cache manager (for example, statistics about how effectively the cache is being used and the quantity of intracell and intercell data access).
2 reports all of the internal performance statistics provided by the 1 setting, plus some additional, detailed performance figures about the Cache Manager (for example, statistics about the number of RPCs sent by the Cache Manager and how long they take to complete; and statistics regarding things such as authentication, access, and PAG information associated with data access).
- -onceonly
Directs the command to gather statistics just one time. Omit this option to have the command continue to probe the Cache Manager for statistics every 30 seconds. If you omit this option, you can use the <Ctrl-c> interrupt signal to halt the command at any time.
- -frequency
Sets the frequency in seconds at which the program initiates probes to the Cache Manager. If you omit this argument, the default is 30 seconds.
- -period
Sets how long the utility runs before exiting, as a number of minutes. If you omit this argument, the default is 10 minutes.
- -debug
Displays additional information as the command runs.
Auditing AFS Events on AIX File Servers
You can audit AFS events on AIX File Servers using an AFS mechanism that transfers audit information from AFS to the AIX auditing system. The following general classes of AFS events can be audited. For a complete list of specific AFS audit events, see Appendix D, AIX Audit Events.
Authentication and Identification Events
Security Events
Privilege Required Events
Object Creation and Deletion Events
Attribute Modification Events
Process Control Events
Note: This section assumes familiarity with the AIX auditing system. For more information, see the AIX System Management Guide for the version of AIX you are using.
Configuring AFS Auditing on AIX File Servers
The directory /usr/afs/local/audit contains three files that contain the information needed to configure AIX File Servers to audit AFS events:
The events.sample file contains information on auditable AFS events. The contents of this file are integrated into the corresponding AIX events file (/etc/security/audit/events).
The config.sample file defines the six classes of AFS audit events and the events that make up each class. It also defines the classes of AFS audit events to audit for the File Server, which runs as the local superuser root. The contents of this file must be integrated into the corresponding AIX config file (/etc/security/audit/config).
The objects.sample file contains a list of information about audited files. You must only audit files in the local file space. The contents of this file must be integrated into the corresponding AIX objects file (/etc/security/audit/objects).
Once you have properly configured these files to include the AFS-relevant information, use the AIX auditing system to start up and shut down the auditing.
To enable AFS auditing
Create the following string in the file /usr/afs/local/Audit on each File Server on which you plan to audit AFS events:
AFS_AUDIT_AllEventsIssue the bos restart command (with the -all flag) to stop and restart all server processes on each File Server. For instructions on using this command, see Stopping and Immediately Restarting Processes.
To disable AFS auditing
Remove the contents of the file /usr/afs/local/Audit on each File Server for which you are no longer interested in auditing AFS events.
Issue the bos restart command (with the -all flag) to stop and restart all server processes on each File Server. For instructions on using this command, see Stopping and Immediately Restarting Processes.